


What are Unix Pipes?
Unix pipes are multiple terminal commands chained together by the pipe operator ("|"), so that the output of one command feeds into the input of the next, very similar to what we know from popular data prep/ETL tools like Tableau Prep, Alteryx or Knime. They work out of the box on Linux or MacOS. You can download Git Bash to be able to run the Bash commands mentioned in this blog post in a Windows environment.
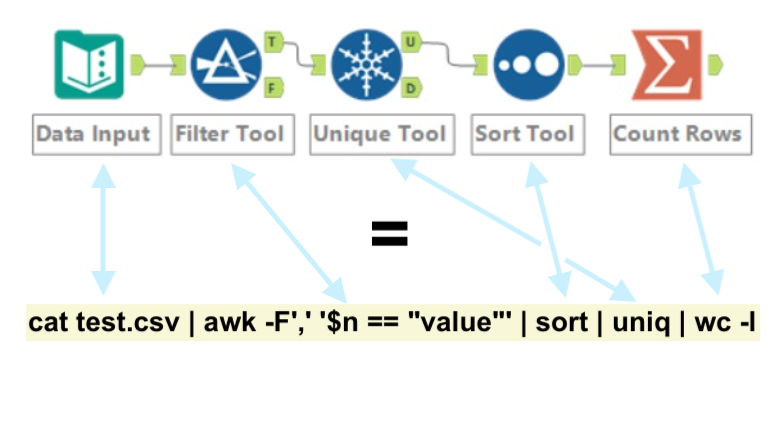
How does the Pipe Operator Work?
When you run a single command in the terminal, its output is displayed on your screen (= written to the standard output) and then disappears. You see the result but can't do anything more with it. The pipe operator changes this by redirecting the standard output to the standard input of another command, creating a data pipeline between processes. So the exact output you'd see written to the terminal becomes the data, separated by newlines. The newline convention creates composability between tools. Bytes move from one process to another in the order they're produced.
Example 1 - Filtering & Counting
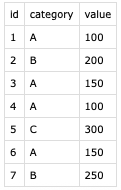
How many different values are in the data for category 'A'?
cat test.csv | tail -n +2 | awk -F',' '$2 == "A"' | cut -d',' -f2,3 | sort | uniq | wc -l |
This Unix pipe can be run from the terminal and returns the number 2, answering the question. It's a chain of distinct transformation steps. Let's break it down step by step and see what each command (= 'tool') does:
cat test.csv |
output the full contents of the csv file (newline separates rows) |
tail -n +2 |
take only rows 2+ from the contents (remove header) |
awk -F',' '$2 == "A"' |
filter to keep only rows with value 'A' in 2nd column (like WHERE category = 'A' in SQL) |
cut -d',' -f2,3 |
keep only columns 2 & 3 (delimiter=',') (like SELECT in SQL) |
sort |
sort the rows, so duplicates appear after one another |
uniq |
keep only unique ['category', 'value'] combinations |
wc -l |
the word count command, but with '-l' set it counts rows |
So, we did a little aggregation to answer the question in just one line of code, pretty neat! Keeping 2 columns in the cut step was a little redundant of course, after having filtered on 'category' already, but a good example of using the cut command to get a slice of columns from the original data. The docs for any of those commands can be produced with the man command. This for example shows the docs for the cat command:
man cat |
Example 2 - Cleaning a Terrible CSV File
Let's now try something harder. For demonstration I've generated a csv file (God bless LLMs) that showcases some messy yet realistic transaction data:
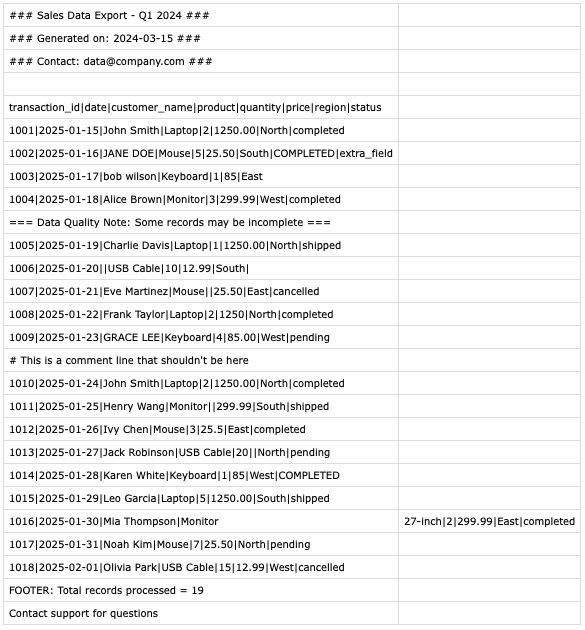
We've all probably struggled with a file like this before. Optimized more for the human eye than for ingestion tools.
The parser I used obviously doesn't interpret it correctly. Let's clean it with a Unix pipe! This file is actually so terrible, that it's probably best to treat it in two steps, handling the header and the data separately. This way we can filter out the non-data rows easier. For this we'll make use of the operators '>' and '>>' that also redirect the standard output, like '|' does. '>' writes to a specified file (overwrites if pre-existing). '>>' writes to a file in append mode, adding lines.
Part 1 - Header Extraction
The header is on line 5. So let's extract the header first and write it to a new file:
head -5 test.csv | tail -1 | tr '|' ',' > test_cleaned.csv |
head -5 |
extract the first 5 lines of the file |
tail -1 |
keep only the last line of the incoming data (= header) |
tr '|' ',' |
change delimiter: translate every '|' to a ',' |
> |
redirect standard output to file (create or overwrite) |
Part 2 - Cleaning the Data
Let's do it step by step this time. The pipe can be constructed one step at a time, always running the pipe until the current step and verifying via the terminal output. For long files, a temporary head -n 25 can be placed at the end of the pipe to avoid cluttering the terminal. For this blog, let's verify with just some sample rows after each step.
1) Drop all non-data rows
We can make use of the fact that all relevant rows start with a 4-digit id. Using grep makes cat unnecessary at the start of the pipe:
grep -E '^\d{4}\|' test.csv |
grep -E |
RegEx matching: return all rows from file that match the pattern |
'^\d{4}\|' |
RegEx pattern: Match any row starting with 4 digits ('^' = start of line) |

2) Enforce 8-column structure
We can use the cut command again to keep only 8 columns, with the delimiter specified to '|'.
cut -d'|' -f1-8 |

3) Case matching
Convert columns 3 and 8 to lowercase.
awk -F'|' 'BEGIN{OFS="|"} {$3 = tolower($3); $8 = tolower($8); print}' |
awk |
runs a small script over each line, ideal for column-based operations |
-F'|' |
set the correct delimiter |
BEGIN{OFS="|"} |
needed to preserve the '|' delimiter |
$3 = tolower($3) |
convert 3rd column to lowercase |
$8 = tolower($8) |
convert 8th column to lowercase |
print |
output the complete line |


4) Change delimiter
Add quotes around all fields & change the delimiter from '|' to ','.
sed 's/|/","/g; s/^/"/; s/$/"/' |
sed |
'stream editor', RegEx-capable find-and-replace type operations (s/pattern/replacement/flags) |
s/|/","/g |
substitutes '|' with ',' and adds quotes around it (g=global, else would stop after first match) |
s/^/"/ |
adds a quote at every line beginning |
s/$/"/ |
adds a quote at every line end |

5) Result & Complete Pipe
grep -E '^[0-9]{4}\|' test.csv | \
cut -d'|' -f1-8 | \
awk -F'|' 'BEGIN{OFS="|"} {$3 = tolower($3); $8 = tolower($8); print}' | \
sed 's/|/","/g; s/^/"/; s/$/"/' \
>> test_cleaned.csv |
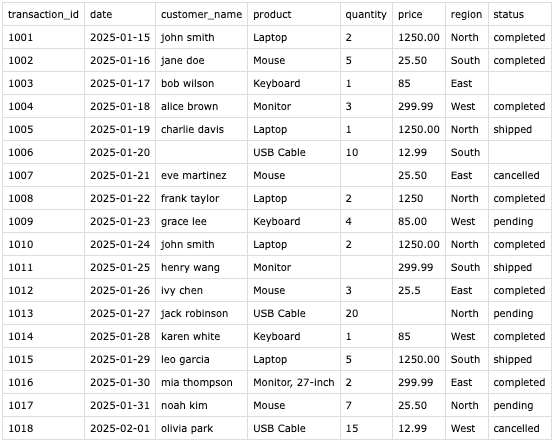
3 Quick Analyses on the Data
Transaction Count by Region
tail -n +2 test_cleaned.csv | awk -F',' '{print $(NF-1)}' | tr -d '"' | sort | uniq -c | sort -rn |
Output:
6 North
4 West
4 South
4 East
Identification of Repeat Customers
cut -d',' -f3 test_cleaned.csv | tr -d '"' | grep -v '^$' | sort | uniq -c | awk '$1 > 1 {print "Customer:", $2, $3, "- Purchases:", $1}' |
Output:
Customer: john smith - Purchases: 2
Distribution of Orders by Status
tail -n +2 test_cleaned.csv | awk -F',' '{print $NF}' | tr -d '"' | grep -v '^$' | sort | uniq -c | sort -rn |
Output:
8 completed
3 shipped
3 pending
2 cancelled
Reading
Jeroen Janssens - Data Science at the Command Line
https://linuxhint.com/50_sed_command_examples/
https://tldp.org/LDP/abs/html/